 Artificial Neural Networks Optimization using Genetic Algorithm with Python
Artificial Neural Networks Optimization using Genetic Algorithm with Python
 Artificial Neural Networks Optimization using Genetic Algorithm with Python
Artificial Neural Networks Optimization using Genetic Algorithm with PythonThis tutorial explains the usage of the genetic algorithm for optimizing the network weights of an Artificial Neural Network for improved performance.
Complete Python Implementation
The Python implementation for such project has three Python files:
- GA.py for implementing GA functions.
- ANN.py for implementing ANN functions.
- Third file for calling such functions through a number of generations. This is the main file of the project.
Main Project File Implementation
The third file is the main file because it connects all functions. It reads the features and the class labels files, filters features based on the standard deviation, creates the ANN architecture, generates the initial solutions, loops through a number of generations by calculating the fitness values for all solutions, selecting best parents, applying crossover and mutation, and finally creating the new population. Its implementation is given below. Such a file defines the GA parameters such as a number of solutions per population, number of selected parents, mutation percent, and number of generations. You can try different values for them.
import numpy
import GA
import pickle
import ANN
import matplotlib.pyplot
f = open("dataset_features.pkl", "rb")
data_inputs2 = pickle.load(f)
f.close()
features_STDs = numpy.std(a=data_inputs2, axis=0)
data_inputs = data_inputs2[:, features_STDs>50]
f = open("outputs.pkl", "rb")
data_outputs = pickle.load(f)
f.close()
#Genetic algorithm parameters:
# Mating Pool Size (Number of Parents)
# Population Size
# Number of Generations
# Mutation Percent
sol_per_pop = 8
num_parents_mating = 4
num_generations = 1000
mutation_percent = 10
#Creating the initial population.
initial_pop_weights = []
for curr_sol in numpy.arange(0, sol_per_pop):
HL1_neurons = 150
input_HL1_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(data_inputs.shape[1], HL1_neurons))
HL2_neurons = 60
HL1_HL2_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL1_neurons, HL2_neurons))
output_neurons = 4
HL2_output_weights = numpy.random.uniform(low=-0.1, high=0.1,
size=(HL2_neurons, output_neurons))
initial_pop_weights.append(numpy.array([input_HL1_weights,
HL1_HL2_weights,
HL2_output_weights]))
pop_weights_mat = numpy.array(initial_pop_weights)
pop_weights_vector = GA.mat_to_vector(pop_weights_mat)
best_outputs = []
accuracies = numpy.empty(shape=(num_generations))
for generation in range(num_generations):
print("Generation : ", generation)
# converting the solutions from being vectors to matrices.
pop_weights_mat = GA.vector_to_mat(pop_weights_vector,
pop_weights_mat)
# Measuring the fitness of each chromosome in the population.
fitness = ANN.fitness(pop_weights_mat,
data_inputs,
data_outputs,
activation="sigmoid")
accuracies[generation] = fitness[0]
print("Fitness")
print(fitness)
# Selecting the best parents in the population for mating.
parents = GA.select_mating_pool(pop_weights_vector,
fitness.copy(),
num_parents_mating)
print("Parents")
print(parents)
# Generating next generation using crossover.
offspring_crossover = GA.crossover(parents,
offspring_size=(pop_weights_vector.shape[0]-parents.shape[0], pop_weights_vector.shape[1]))
print("Crossover")
print(offspring_crossover)
# Adding some variations to the offsrping using mutation.
offspring_mutation = GA.mutation(offspring_crossover,
mutation_percent=mutation_percent)
print("Mutation")
print(offspring_mutation)
# Creating the new population based on the parents and offspring.
pop_weights_vector[0:parents.shape[0], :] = parents
pop_weights_vector[parents.shape[0]:, :] = offspring_mutation
pop_weights_mat = GA.vector_to_mat(pop_weights_vector, pop_weights_mat)
best_weights = pop_weights_mat [0, :]
acc, predictions = ANN.predict_outputs(best_weights, data_inputs, data_outputs, activation="sigmoid")
print("Accuracy of the best solution is : ", acc)
matplotlib.pyplot.plot(accuracies, linewidth=5, color="black")
matplotlib.pyplot.xlabel("Iteration", fontsize=20)
matplotlib.pyplot.ylabel("Fitness", fontsize=20)
matplotlib.pyplot.xticks(numpy.arange(0, num_generations+1, 100), fontsize=15)
matplotlib.pyplot.yticks(numpy.arange(0, 101, 5), fontsize=15)
f = open("weights_"+str(num_generations)+"_iterations_"+str(mutation_percent)+"%_mutation.pkl", "wb")
pickle.dump(pop_weights_mat, f)
f.close()
Based on 1,000 generations, a plot is created at the end of this file using Matplotlib visualization library that shows how the accuracy changes across each generation. It is shown in the next figure.
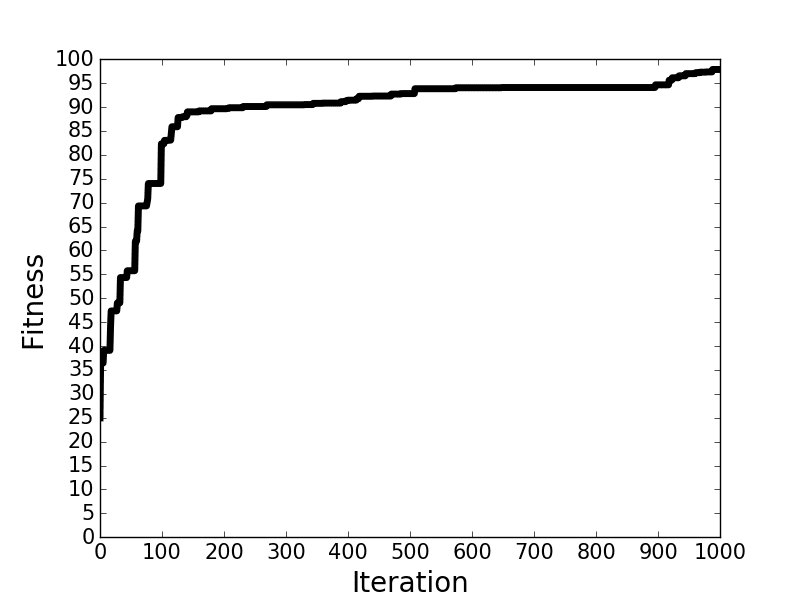
After 1,000 iterations, the accuracy is more than 97%. This is compared to 45% without using an optimization technique as in the previous tutorial. This is an evidence about why results might be bad not because there is something wrong in the model or the data but because no optimization technique is used. Of course, using different values for the parameters such as 10,000 generations might increase the accuracy. At the end of this file, it saves the parameters in matrix form to the disk for use later.
GA.py Implementation
The GA.py file implementation is in listed below. Note that the mutation() function accepts the mutation_percent parameter that defines the number of genes to change their values randomly. It is set to 10% in the main file. Such a file holds the 2 new functions mat_to_vector() and vector_to_mat().
import numpy
import random
# Converting each solution from matrix to vector.
def mat_to_vector(mat_pop_weights):
pop_weights_vector = []
for sol_idx in range(mat_pop_weights.shape[0]):
curr_vector = []
for layer_idx in range(mat_pop_weights.shape[1]):
vector_weights = numpy.reshape(mat_pop_weights[sol_idx, layer_idx], newshape=(mat_pop_weights[sol_idx, layer_idx].size))
curr_vector.extend(vector_weights)
pop_weights_vector.append(curr_vector)
return numpy.array(pop_weights_vector)
# Converting each solution from vector to matrix.
def vector_to_mat(vector_pop_weights, mat_pop_weights):
mat_weights = []
for sol_idx in range(mat_pop_weights.shape[0]):
start = 0
end = 0
for layer_idx in range(mat_pop_weights.shape[1]):
end = end + mat_pop_weights[sol_idx, layer_idx].size
curr_vector = vector_pop_weights[sol_idx, start:end]
mat_layer_weights = numpy.reshape(curr_vector, newshape=(mat_pop_weights[sol_idx, layer_idx].shape))
mat_weights.append(mat_layer_weights)
start = end
return numpy.reshape(mat_weights, newshape=mat_pop_weights.shape)
def select_mating_pool(pop, fitness, num_parents):
# Selecting the best individuals in the current generation as parents for producing the offspring of the next generation.
parents = numpy.empty((num_parents, pop.shape[1]))
for parent_num in range(num_parents):
max_fitness_idx = numpy.where(fitness == numpy.max(fitness))
max_fitness_idx = max_fitness_idx[0][0]
parents[parent_num, :] = pop[max_fitness_idx, :]
fitness[max_fitness_idx] = -99999999999
return parents
def crossover(parents, offspring_size):
offspring = numpy.empty(offspring_size)
# The point at which crossover takes place between two parents. Usually, it is at the center.
crossover_point = numpy.uint8(offspring_size[1]/2)
for k in range(offspring_size[0]):
# Index of the first parent to mate.
parent1_idx = k%parents.shape[0]
# Index of the second parent to mate.
parent2_idx = (k+1)%parents.shape[0]
# The new offspring will have its first half of its genes taken from the first parent.
offspring[k, 0:crossover_point] = parents[parent1_idx, 0:crossover_point]
# The new offspring will have its second half of its genes taken from the second parent.
offspring[k, crossover_point:] = parents[parent2_idx, crossover_point:]
return offspring
def mutation(offspring_crossover, mutation_percent):
num_mutations = numpy.uint8((mutation_percent*offspring_crossover.shape[1])/100)
mutation_indices = numpy.array(random.sample(range(0, offspring_crossover.shape[1]), num_mutations))
# Mutation changes a single gene in each offspring randomly.
for idx in range(offspring_crossover.shape[0]):
# The random value to be added to the gene.
random_value = numpy.random.uniform(-1.0, 1.0, 1)
offspring_crossover[idx, mutation_indices] = offspring_crossover[idx, mutation_indices] + random_value
return offspring_crossover
ANN.py Implementation
Finally, the ANN.py is implemented according to the code listed below. It contains the implementation of the activation functions (sigmoid and ReLU) in addition to the fitness() and predict_outputs() functions to calculate the accuracy.
import numpy
def sigmoid(inpt):
return 1.0 / (1.0 + numpy.exp(-1 * inpt))
def relu(inpt):
result = inpt
result[inpt < 0] = 0
return result
def predict_outputs(weights_mat, data_inputs, data_outputs, activation="relu"):
predictions = numpy.zeros(shape=(data_inputs.shape[0]))
for sample_idx in range(data_inputs.shape[0]):
r1 = data_inputs[sample_idx, :]
for curr_weights in weights_mat:
r1 = numpy.matmul(a=r1, b=curr_weights)
if activation == "relu":
r1 = relu(r1)
elif activation == "sigmoid":
r1 = sigmoid(r1)
predicted_label = numpy.where(r1 == numpy.max(r1))[0][0]
predictions[sample_idx] = predicted_label
correct_predictions = numpy.where(predictions == data_outputs)[0].size
accuracy = (correct_predictions / data_outputs.size) * 100
return accuracy, predictions
def fitness(weights_mat, data_inputs, data_outputs, activation="relu"):
accuracy = numpy.empty(shape=(weights_mat.shape[0]))
for sol_idx in range(weights_mat.shape[0]):
curr_sol_mat = weights_mat[sol_idx, :]
accuracy[sol_idx], _ = predict_outputs(curr_sol_mat, data_inputs, data_outputs, activation=activation)
return accuracy
For Contacting the Author
- E-mail: ahmed.f.gad@gmail.com
- LinkedIn: https://linkedin.com/in/ahmedfgad/
- KDnuggets: https://www.kdnuggets.com/author/ahmed-gad
- YouTube: https://youtube.com/AhmedGadFCIT
- TowardsDataScience: https://towardsdatascience.com/@ahmedfgad
- GitHub: https://github.com/ahmedfgad
Original. Reposted with permission.
Bio: Ahmed Gad received his B.Sc. degree with excellent with honors in information technology from the Faculty of Computers and Information (FCI), Menoufia University, Egypt, in July 2015. For being ranked first in his faculty, he was recommended to work as a teaching assistant in one of the Egyptian institutes in 2015 and then in 2016 to work as a teaching assistant and a researcher in his faculty. His current research interests include deep learning, machine learning, artificial intelligence, digital signal processing, and computer vision.
Related:
- Artificial Neural Network Implementation using NumPy and Image Classification
- Genetic Algorithm Implementation in Python
- Is Learning Rate Useful in Artificial Neural Networks?