DeepMind Unveils Agent57, the First AI Agents that Outperforms Human Benchmarks in 57 Atari Games
The new reinforcement learning agent innovates over previous architectures achieving one of the most important milestones in the AI space.

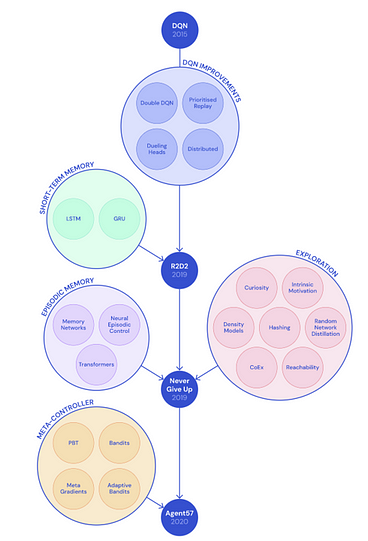
Games have long been considered one of the top environments to measure general intelligence capabilities of artificial intelligence(AI) agents. In particular, game environments have achieved a lot of popularity within the deep reinforcement learning(DRL) community establishing several benchmarks to evaluate the competency of different DRL methods. Among those benchmarks, Atari57 is a collection of 57 Arari games that stands as one of the most difficult challenges for DRL agents. Many DRL agents have achieved great results on individual games but failed when evaluated across the entire collection. Recently, DeepMind unveiled Agent57, the first DRL agent able to outperform the standard human benchmark in all 57 Atari games.
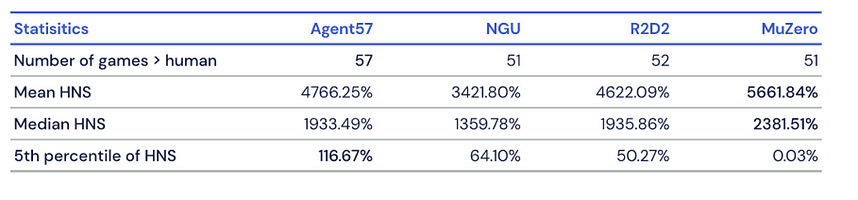
What makes Atari57 such a challenging benchmark is the diversity of games and tasks. The goal of the environment is to evaluate how many of those tasks a DRL agent is able to master. The standard way to evaluate performance in the Atari57 environment have come to be known as the human normalized scores(HNS). Despite all efforts, no single DRL algorithm has been able to achieve over 100% HNS on all 57 Atari games with one set of hyperparameters. Indeed, state of the art algorithms in model-based DRL, MuZero, and in model-free DRL, R2D2 surpass 100% HNS on 51 and 52 games, respectively. The following figure illustrates the performance of DRL agents over time against the HNS benchmark.

The Road to Agent57: The Evolution of Reinforcement Learning Methods
The first attempt to tackle the Atari57 challenge was the Deep Q-network agent (DQN) and subsequently variations of it. Despite the notable advancements, most DRL agents failed to generalize knowledge diverse tasks. Games such as Montezuma’s Revenge and Pitfall require extensive exploration to obtain good performance. This makes them vulnerable to the famous exploration-exploitation problem: should one keep performing behaviours one knows works (exploit), or should one try something new (explore) to discover new strategies that might be even more successful?
Other Atari games such as Solaris and Skiing are long-term credit assignment problems: in these games, it’s challenging to match the consequences of an agents’ actions to the rewards it receives.
To address some of those challenges, the DQN model evolved incorporating several advancements in the deep learning space. Specifically, the development of techniques such as short-term memory and episodic memory played an important role in the development of more advanced DRL agents.
Short Term Memory
Memory has been one of the key elements in recent advancements in DRL methods. Techniques such as long long-Short Term Memory (LSTM) have been at the forefront of the implementation of short-term-memory methods that allow DRL agents to account previous observations into their decision making. An interesting set of capabilities in DRL agents are developed when combining short-term-memory with off-policy learning methods. Conceptually, off-policy learning methods allow a DRL agent to learn about optimal actions even when not performing those actions. At any given point, an agent might be taking random actions but can still learn what the best possible action would be. To illustrate this concept imagine a DRL agent that is learning what it might choose to remember when looking for an apple (ex: where the apple is located). This is different to what the agent might choose to remember if looking for an orange but, even then, the agent could still learn how to find the apple if it came across the apple by chance.
In the context of the Atari57 challenge, the Recurrent Replay Distributed DQN (R2D2) agent combined off-policy learning and memory to achieve remarkable results although it failed short of completing the entire challenge.
Episodic Memory
An interesting complement to short-term-memory was the development of episodic memory methods. Conceptually, these methods allow a DRL agent to detect when new parts of a game are encountered, so the agent can explore these newer parts of the game in case they yield rewards. From that perspective, episodic memory facilitates the development exploration policies which complement the exploitation policies which are mostly focus on the agent’s learning.
The Never Give Up (NGU) agent was designed to augment R2D2 with episodic memory capabilities. As a significant milestone, NGU was the first agent to obtain positive rewards, without domain knowledge on the Pitfall game. Not surprisingly, NGU became the underlying model of the Agent57 architecture.
Agent57
Agent57 is built on top of NGU emphasizing on two of its key principles:
- Distributed Reinforcement Learning
- Curiosity Driven Exploration
Just like NGU and R2D2, Agent57 is based on a distributed reinforcement learning model. As such, Agent57 decouples the data collection and the learning processes by having many actors feed data to a central prioritized replay buffer. A learner can then sample training data from this buffer. The learner uses these replayed experiences to construct loss functions, by which it estimates the cost of actions or events. Then, it updates the parameters of its neural network by minimizing losses. Finally, each actor shares the same network architecture as the learner, but with its own copy of the weights.

Another key concept in Agent57 is curiosity driven exploration. This technique is designed to better balance the exploration-exploitation tradeoffs in DRL agents. In addition to that famous trade-off, DRL agents tackling the Atari57 challenge also need to balance the time horizon of those rewards. Some tasks will require long time horizons (e.g. Skiing, Solaris), where valuing rewards that will be earned in the far future might be important for eventually learning a good exploitative policy, or even to learn a good policy at all. At the same time, other tasks may be slow and unstable to learn if future rewards are overly weighted. This short-long-term trade-off has been particularly hard to solve in DRL agents.
To address this challenge, many DRL methods have relied on meta-controller architectures that that controls the amount of experience produced with different policies, with a variable-length time horizon and importance attributed to novelty.
Now that we have all these concepts together, we can probably better understand the architecture of Agent57. Conceptually, Agent57 can be seen as the combination of the NGU architecture with a meta-controller. Functionally, Agent57 computes a mixture of long and short term intrinsic motivation to explore and learn a family of policies, where the choice of policy is selected by the meta-controller. The meta-controller allows each actor of the agent to choose a different trade-off between near vs. long term performance, as well as exploring new states vs. exploiting what’s already known. Agent57 exhibited several improvements over the NGU and R2D2 architectures such as adaptive exploration and backpropagation through time.
DeepMind benchmarked Agent57 against the entire set of Atari57 games. The agent was able to complete the entire challenge surpassing the performance of previous DRL agents. Agent57 was able to scale with increasing amounts of computation: the longer it trained, the higher its score got. Although the computational costs are prohibited to most organizations.
Agent57 represents a major milestone in the deep learning space as it’s the first DRL agent to complete the Atari57 benchmark. Beyond that, the Agent57 architecture can be applicable to many deep learning problems as it solves important challenges such as exploration and exploitation and long-term credit assignment. Its going to be interesting to see the next evolution of this architecture.
Original. Reposted with permission.
Related:
- DeepMind Unveils MuZero, a New Agent that Mastered Chess, Shogi, Atari and Go Without Knowing the Rules
- The Reinforcement-Learning Methods that Allow AlphaStar to Outcompete Almost All Human Players at StarCraft II
- What just happened in the world of AI?