Facebook Open Sources ReBeL, a New Reinforcement Learning Agent
The new model tries to recreate the reinforcement learning and search methods used by AlphaZero in imperfect information scenarios.

I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Poker has been considered by many the core inspiration for the formalization of game theory. John von Neuman was reportedly an avid poker fan and use many analogies of the card game while creating the foundation of game-theory. With the advent of artificial intelligence(AI) there have been many attempts to master different forms of poker, most of them with very limited results. Last year, researchers from Facebook and Carnegie Mellon University astonishing the AI world by unveiling Pluribus, an AI agent that beat elite human professional players in the most popular and widely played poker format in the world: six-player no-limit Texas Hold’em poker. Since then, a question that has hunted AI researchers is whether the skills acquired by models like Pluribus can be used in other imperfect information games. A few days ago, Facebook again used poker as the inspiration for Recursive Belief-based Learning (ReBeL), a reinforcement learning model that is able to master several imperfect-information games.
The inspiration from ReBeL comes from DeepMind’s AlphaZero. After setting up new records in the Go game with the development of AlphaGo, DeepMind expanded iits efforts to other perfect-information games such as Chess, or Shogi. The result was AlphaZero, a reinforcement agent that was able to master all these games from scratch. Of course, recreating the magic of AlphaZero in imperfect-information games like poker entails a different level of complexity.
Games like poker in which players keep their cards secret represent a major obstacle for reinforcement learning + search algorithms. Most of these techniques assume that each player’s action has a fixed value regardless of the probability of that action being executed. For instance, in chess, a good move is good regardless of whether is played or not. Now let’s think about a game like poker in which the players bluff all the time. In many scenarios, the value of a bluff action diminishes the more its used as the opponents can adjust their strategy to it. How could we possibly leverage reinforcement learning + search methods across many imperfect-information games.
Enter ReBeL
The idea behind ReBeL is SO SIMPLE as it is clever. If AlphaZero showed success with reinforcement learning + search strategies in perfect-information games, then why not to transform imperfect-information games to perfect-information equivalents? I know, I know, it sounds too good to be true but let’s look at an example.
Let’s imagine a simplified version of poker in which a single card is dealt to each player which can then choose between three actions: fold, call or raise. Now consider a variation of this game in which the cards are not dealt to the players directly but, instead, they can be seen only by an third-party referee. Instead of taking an action directly, the players will announce how likely they are to take a specific action given the current hand. The referee will take an action based on the player’s analysis. In terms of strategy, this modified game is identical to the original game with the difference that it contains no private information. Instead, the modified game can be considered a continuous-state perfect-information game.
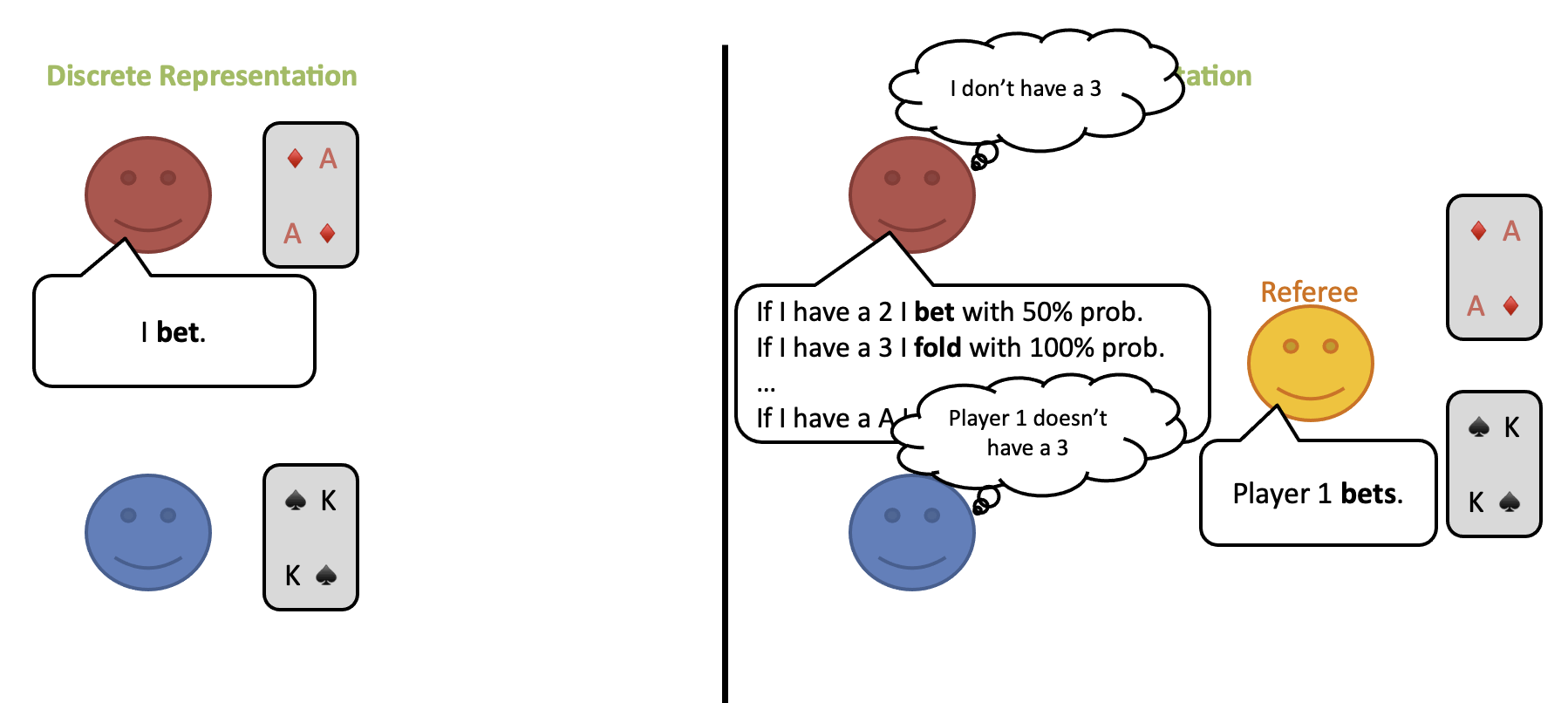
The transformation of an imperfect-information game to a perfect-information environment, opens the door to utilizing the same techniques that worked for AlphaZero. The main challenge at this point is efficiency, as the search space is fairly larger than most perfect-information games. To address this, ReBeL uses an optimization technique known as counterfactual regret minimization (CFR) to improve the efficiency of the search.
Facebook evaluated ReBeL in two games: heads-up no-limit Texas Hold’em and Liar’s Dice with very strong performance in both.
ReBeL represents an important milestone in order to use reinforcement learning + search in order to generically solve imperfect-information games. There are still plenty of challenges including the fact that it knows the rules of the game in advance which is not the case of many real world scenarios. Facebook also open sourced the implementation of the Liar’s Dice game to allow the research community to improve in these ideas.
Original. Reposted with permission.
Related:
- Facebook Open Sourced New Frameworks to Advance Deep Learning Research
- Microsoft and Google Open Sourced These Frameworks Based on Their Work Scaling Deep Learning Training
- Remembering Pluribus: The Techniques that Facebook Used to Master World’s Most Difficult Poker Game