 17 More Must-Know Data Science Interview Questions and Answers, Part 3
17 More Must-Know Data Science Interview Questions and Answers, Part 3
 17 More Must-Know Data Science Interview Questions and Answers, Part 3
17 More Must-Know Data Science Interview Questions and Answers, Part 3
The third and final part of 17 new must-know Data Science interview questions and answers covers A/B testing, data visualization, Twitter influence evaluation, and Big Data quality.
Q15. In an A/B test, how can we ensure that assignment to the various buckets is truly random?
Matthew Mayo answers:
First, let’s consider how we can best ensure comparability between buckets prior to bucket assignment, without knowledge of any distribution of attributes in the population.
The answer here is simple: random selection and bucket assignment. Random selection and assignment to buckets without regard to any attribute of the population is a statistically sound approach, given a large enough population to draw from.
For example, let’s say you are testing a change to a website feature and are interested in response from only a particular region, the US. By first splitting into 2 groups (control and treatment) without regard to user region (and given a large enough population size), assignment of US visitors should be split between these groups. From these 2 buckets, visitor attributes can then be inspected for the purposes of testing, such as:
if (region == "US" && bucket == "treatment"):
# do something treatment-related here
else:
if (region == "US" && bucket == "control"):
# do something control-related here
else:
# catch-all for non-US (and not relevant to testing scenario)
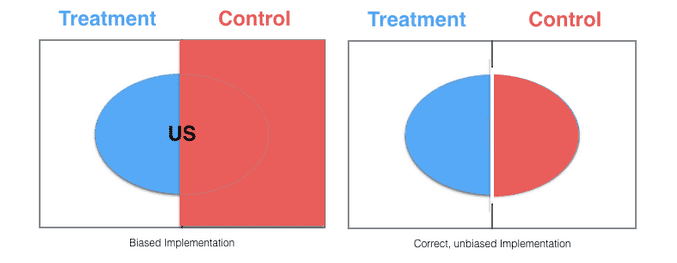
Image Source.
Bear in mind that, even after performing a round of random bucket assignment, statistical testing can be utilized to inspect/verify random distribution of bucket member attributes (e.g. ensure that significantly more US visitors did not get assigned to bucket A). If not, a new random assignment can be attempted (with a similar inspection/verification process), or -- if it is determined that the population does not conform to a cooperative distribution -- an approach such as the following can be pursued.
If we happen to know of some uneven population attribute distribution prior to bucket assignment, stratified random sampling may be helpful in ensuring more evenly distributed sampling. Such a strategy can help eliminate selection bias, which is the archenemy of A/B testing.
References:
- Detecting and avoiding bucket imbalance in A/B tests
- What are the methods to ensure that the population split for A/B test is random?
- A/B Testing
Q16. How would you conduct an A/B test on an opt-in feature?
Matthew Mayo answers:
This seems to be a somewhat ambiguous question with a variety of interpretable meanings (an idea supported by this post). Let's first look at the different possible interpretations of this questions and go from there.
- How would you conduct an A/B test on an opt-in version of a feature to a non-opt-in-version?
This would not allow for a fair or meaningful A/B test, since one bucket would be filled from the entire site's users, while the other would be filled from the group which has already opted in. Such a test would be akin to comparing some apples to all oranges, and thus ill-advised. - How would you conduct an A/B test on the adoption (or use) of an opt-in feature (i.e. test the actual opting-in)?
This would be testing the actual opting in -- such as the testing between 2 versions of a "click here to sign up" feature -- and as such is just a regular A/B test (see the above question for some insight). - How would you conduct an A/B test on different versions of an opt-in feature (i.e. for those having already opted in)?
This could, again, be construed as one of a few meanings, but I intend to approach it as a complex scenario of the chaining together of events, expanded upon below.

Let's flesh out #3 from the list above. Let's first look at a simple chaining of events which can be tested, and then generalize. Suppose you are performing an A/B test on an email campaign. Let's say the variable will be subject line, and that content remains constant between the 2. Suppose the subject lines are as follows:
- We have something for you
- The greatest online data science courses are free this weekend! Try now, no commitment!
Contrived, to be sure. All else aside, intuition would say that subject #2 would get more action.
But beyond that, there is psychology at play. Even though the content which follows after clicking either of the subjects is the same, the individual clicking the second subject could reasonably be assumed to have a higher level of excitement and anticipation of what is to follow. This difference in expectations and level of commitment between the groups may lead to a higher percentage of click-throughs for those in the bucket with subject line #2 -- again, even with the same content.
Pivoting slightly... How would you conduct an A/B test on different versions of an opt-in feature (i.e. for those having already opted in)?
If my interpretation of evaluating a series of chained events is correct, such an A/B test could commence with different feeder locations to the same opt-in -- of the same content -- and move to to different follow-up landing spots after opt-in, with the intent of measuring what users do on the resulting landing page being the goal.
Do different originating locations to the same opt-in procedure result in different follow-up behavior? Sure, it's still an A/B test, with the same goals, setup, and evaluation; however, the exact user psychology being measured is different.
What does this have to do with an interview question? Beyond being able to identify the basic ideas of A/B testing, being able to walk through imprecise questions is an asset to people working in analytics and data science.
Q17. How to determine the influence of a Twitter user?
Gregory Piatetsky answers:
Social networks are at the center of today's web, and determining the influence in a social network is a huge area of research. Twitter influence is a narrow area within the overall social network influence research.
The influence of a Twitter user goes beyond the simple number of followers. We also want to examine how effective are tweets - how likely they are to be retweeted, favorited, or the links inside clicked upon. What exactly is an influential user depends on the definition - different types of influence discussed included celebrities, opinion leaders, influencers, discussers, innovators, topical experts, curators, commentators, and more.
A key challenge is to compute influence efficiently. An additional problem on Twitter is separating humans and bots.
Common measures used to quantify influence on Twitter include many versions of network centrality - how important is the node within the network, and PageRank-based metrics.

KDnuggets Twitter Social Network, as visualized in NodeXL in May 2014.
Traditional network measures used include
- Closeness Centrality, based on the length of the shortest paths from a node to everyone else. It measures the visibility or accessibility of each node with respect to the entire network
- Betweenness centrality considers for each node i all the shortest paths that should pass through i to connect all the other nodes in the network. It measures the ability of each node to facilitate communication within the network.
Other proposed measures include retweet impact (how likely is the tweet be retweeted) and variations of PageRank, such as TunkRank - see A Twitter Analog to PageRank.
An important refinement to overall influence is looking at influence within a topic - done by Agilience and RightRelevant. For instance, Justin Bieber may have high influence overall, but he is less influential than KDnuggets in the area of Data Science.
Twitter provides a REST API which allows access to key measures, but with limits on the number of requests and the data returned.
There were a number of websites that measured Twitter user influence, but many of their business models did not pan out, since many of them were acquired or went out of business. Ones which are currently active include the following:
Free:
- Agilience (KDnuggets is #1 in Machine Learning, #1 is Data Mining, #2 in Data Science)
- Klout, klout.com (KDnuggets Klout score is 79)
- Influence Tracker, www.influencetracker.com , KDnuggets influence metric 39.2
- Right Relevance - measures specific relevance of twitter users within a topic.
Paid:
- Brandwatch (bought PeerIndex)
- Hubspot
- Simplymeasured
Relevant KDnuggets posts:
- Agilience Top Data Mining, Data Science Authorities
- 12 Data Analytics Thought Leaders on Twitter
- The 123 Most Influential People in Data Science
- RightRelevance helps find key topics, top influencers in Big Data, Data Science, and Beyond
Relevant KDnuggets tags:
For a more in-depth analysis, see technical articles below:
- What is a good measure of the influence of a Twitter user?, Quora
- Measuring User Influence in Twitter: The Million Follower Fallacy, AAAI, 2010
- Measuring user influence on Twitter: A survey, arXiv, 2015
- Measuring Influence on Twitter, I. Anger and C. Kittl
- A Data Scientist Explains How To Maximize Your Influence On Twitter, Business Insider, 2014
Related: